Introducción
Los entornos multi data-center con Kafka presentan desafíos significativos en términos de resiliencia y continuidad del negocio. Uno de los problemas más comunes es la operatoria manual al momento de un failover cuando se pierde la conexión con un cluster de Kafka, lo cual puede resultar en demoras significativas y riesgo de pérdida de datos. En esta oportunidad nos gustaría concentrarnos en un caso particular, en el cual uno de nuestros clientes nos presentó una situación en la cual una pérdida de conexión a su clúster provocaba una demora de varios días antes de poder recuperar los mensajes perdidos en la interrupción y volver al esquema inicial. Para abordar esta problemática, se han implementado soluciones basadas en replicación para disminuir la mayor cantidad de operatoria manual posible e implementado a través de Infraestructura como código, como Confluent cluster linking y el uso de MirrorMaker 2. Estas soluciones permiten replicar los tópicos entre clusters de distintos datacenters, minimizando el impacto de mensajes sin consumir en un cluster caído y mejorando la eficiencia del proceso de failover.
Activo-activo vs activo-pasivo:
En Kafka, un esquema activo-activo se refiere a un enfoque en el que múltiples clústeres de Kafka están activos y operativos simultáneamente para la replicación y distribución de datos. En este caso, los datos se pueden producir y consumir en cualquiera de los clústeres, lo que permite una mayor disponibilidad y escalabilidad del sistema.
En un esquema activo-activo, los datos se replican entre los clústeres de Kafka, lo que significa que los mensajes enviados a un clúster se copian en otros clústeres de forma asincrónica. Esto proporciona redundancia y tolerancia a fallos, ya que si un clúster se vuelve inaccesible o falla, los datos todavía están disponibles en otros clústeres para su consumo.
La principal diferencia entre un esquema activo-activo y un esquema activo-pasivo en Kafka radica en cómo se maneja la replicación y la disponibilidad de datos.
En un esquema activo-pasivo, que para este caso es el que finalmente adoptamos, sólo un clúster de Kafka está activo y operativo, mientras que los demás clústeres se mantienen en modo pasivo como respaldo. Todos los datos se producen y consumen desde el clúster activo, y si este clúster falla, se activa uno de los clústeres pasivos con todos los mensajes replicados para asumir el rol de clúster activo y continuar con la operación. En este enfoque, puede haber una breve interrupción en el servicio durante el proceso de conmutación por error.
En resumen, la diferencia clave entre un esquema activo-activo y un esquema pasivo-activo en Kafka es que en el primero, múltiples clústeres están activos y operativos simultáneamente para la replicación y distribución de datos, mientras que en el segundo, solo un clúster está activo y los demás actúan como respaldo hasta que sea necesario activarlos.
Herramientas de replicación:
Las herramientas de replicación son soluciones fundamentales para garantizar la disponibilidad y la continuidad del negocio al permitir la copia en tiempo real de datos entre diferentes sistemas o clústeres. Estas herramientas desempeñan un papel crucial en entornos distribuidos y en la gestión de datos críticos. La replicación de datos asegura que la información esté siempre sincronizada y disponible en múltiples ubicaciones geográficas, lo que reduce el riesgo de pérdida de datos y permite una rápida recuperación en caso de fallos. Estas soluciones se han vuelto cada vez más importantes y las dos principales herramientas de replicación son MirrorMaker 2 y Cluster Linking.
MirrorMaker 2
La evolución de MirrorMaker a MirrorMaker 2 marcó un importante avance en la replicación de datos de Apache Kafka. MirrorMaker 2 fue desarrollado para abordar las limitaciones y desafíos encontrados en la versión anterior, con el objetivo de ofrecer una mayor escalabilidad y confiabilidad en los escenarios de replicación entre clústeres.
Una de las principales mejoras introducidas en MirrorMaker 2 es su arquitectura distribuida y asincrónica. A diferencia de su predecesor, que era monolítico y síncrono, MirrorMaker 2 permite una mayor flexibilidad y rendimiento al permitir la replicación paralela de particiones y la transferencia de datos de manera asincrónica. Esto resulta en una mejor utilización de los recursos y una mayor capacidad de adaptación a entornos de alto rendimiento.
Cluster Linking:
Cluster Linking es una solución específica diseñada por Confluent para abordar los desafíos de replicación en entornos multi data-center Es parte de un catálogo de herramientas de administración de kafka, en una plataforma self-managed y una versión cloud fully-managed para algunos proveedores como AWS, Azure y GCP. Esta solución permite la replicación de datos y configuración desde el cluster origen hacia el cluster destino generando tópicos del mismo nombre o con prefijos. Cluster linking garantiza que estos tópicos mirrors contengan la misma información que el cluster fuente, incluyendo sus offsets, el orden y distribución de mensajes en sus particiones.
Ventajas de Cluster Linking sobre MirrorMaker 2:
- Mayor control sobre la replicación: Cluster Linking permite una replicación más precisa y controlada, evitando conflictos de offset y asegurando una alta disponibilidad de los datos.
- Mayor flexibilidad en la configuración: Cluster Linking ofrece mayor flexibilidad en la configuración del esquema activo-pasivo, lo que facilita la migración entre distintos tipos de clusters.
- Cluster linking es un servicio serverless que necesita de menos configuración manual a diferencia de MirrorMaker 2 que si la requiere.
El escenario propuesto:
En nuestro escenario vamos a estar trabajando con 3 clusters de Kafka A, B y C. El cluster A cumple el rol de cluster activo. Luego tenemos el cluster B que es nuestro cluster pasivo. Por último tenemos el cluster C que a diferencia de el A y el B no se levanta hasta el momento en el que haya haya la necesidad de un Disaster Recovery y cumpla el rol del nuevo cluster pasivo.
En este escenario propuesto, se busca establecer una replicación en tiempo real del estado del nuestro cluster Kafka activo, hacia un segundo cluster Kafka pasivo, a través de cluster linking de manera asincrónica.
Toda la infraestructura de Kafka es levantada por Terraform, así también como los estados de los clusters para hacer el Disaster Recovery.
El Disaster Recovery consiste en realizar una promoción del cluster pasivo para que este tome el rol de cluster activo, cambiando el estado de cluster linking a “Failover” deteniendo la replicación y otorgando permisos de escritura a los tópicos. Luego generamos un nuevo cluster C como nuevo cluster pasivo replicando a través de cluster linking del cluster B. Por último redireccionamos los aplicativos hacia el nuevo cluster activo.
Ahora mostraremos los pasos para la creación de la infraestructura.
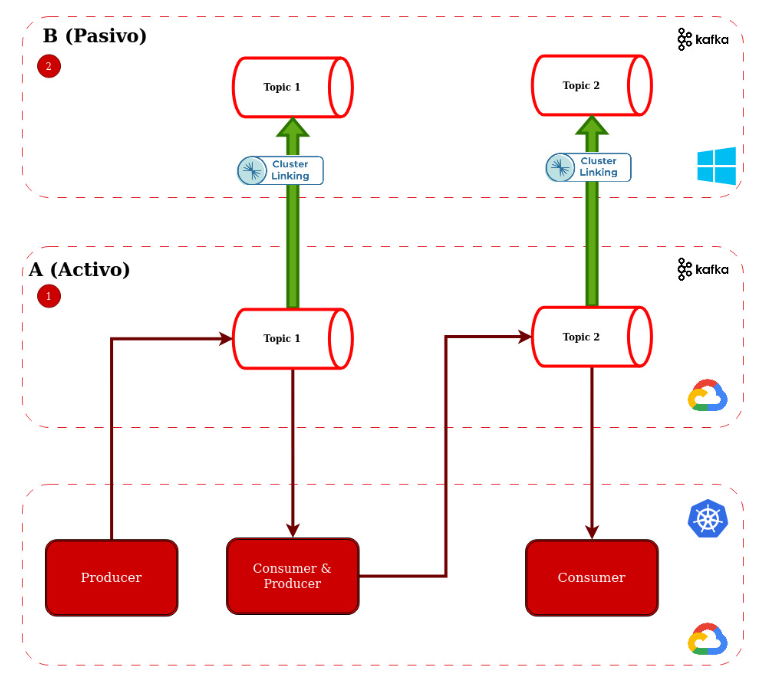
- Creamos el cluster A donde le indicamos que cree los tópicos que vamos a utilizar
- Creamos el cluster B donde le indicamos que cree cluster linking y este se encarga de crear los tópicos replicados del cluster A (Estos tópicos solo tienen permiso de lectura)
A continuación se pueden ver los pasos a seguir para el Disaster Recovery
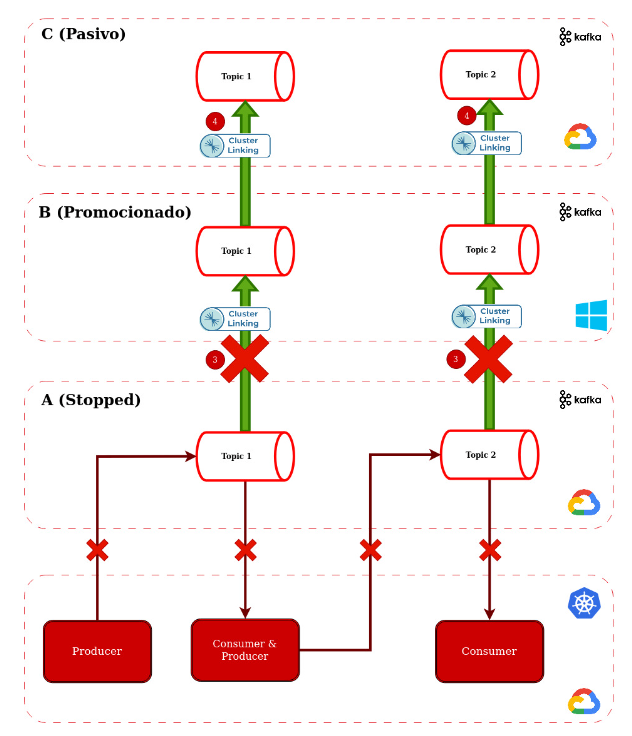
- Ejecutar el pipeline de Terraform designado para el failover. Este se encarga de poner cluster linking en estado “Failover” esto hace que los tópicos tengan permisos de lectura y escritura y deje de replicar del cluster A
- Ejecutamos el pipeline de Terraform designado a crear el cluster C. Este se crea con cluster linking replicando del cluster B
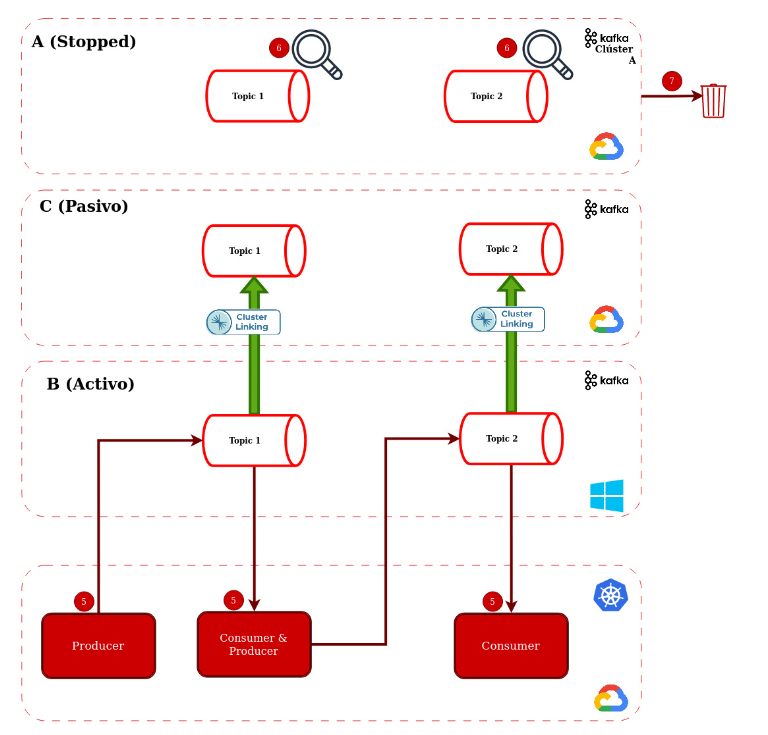
- Cambiamos las credenciales de los aplicativos para que se comuniquen con el cluster B
- Hacemos el proceso de verificación de integridad de mensajes para tener la certeza de que no tuvimos pérdida de mensajes
- Eliminamos el cluster A
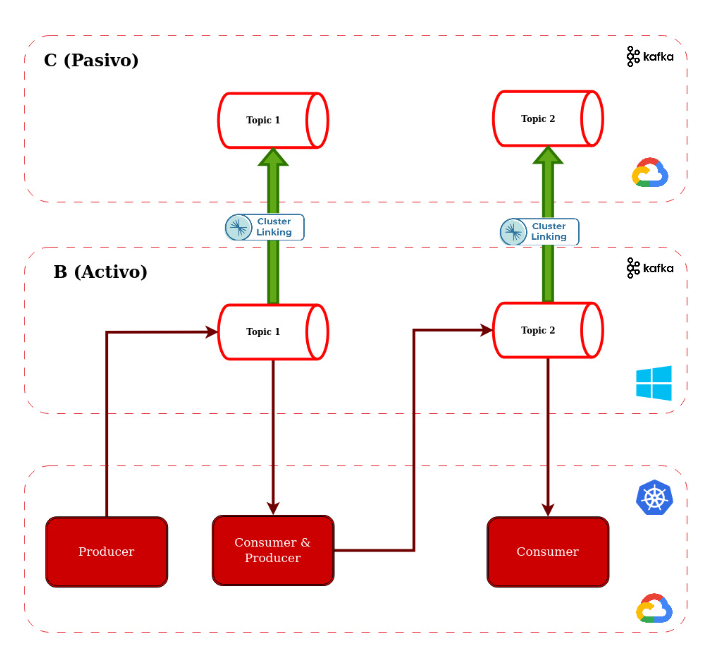
Beneficios y ventajas:
La implementación de este escenario propuesto brinda varios beneficios significativos. En primer lugar, se logra una mayor resiliencia y disponibilidad del sistema al minimizar el impacto de los fallos en un cluster caído, ya que ahora cuando haya un fallo y sea necesario hacer un failover con tan solo correr 2 pipelines y cambiar credenciales en los aplicativos todo volvería a funcionar con normalidad. Además, se mejora la eficiencia del proceso de failover utilizando Infrastructure as Code, evitando la operatoria manual que puede resultar en demoras significativas.
Además, este enfoque permite mantener consumidores y productores en los otros datacenters o proveedores de nube, lo que proporciona una mayor flexibilidad y escalabilidad. Al apuntar a cada cluster de forma separada, se pueden realizar cambios en la implementación o el despliegue de manera más ágil y controlada.
Consideraciones y límites:
Es importante tener en cuenta que, aunque la replicación de clusters mejora significativamente la resiliencia y la continuidad del negocio, no se puede garantizar la replicación de todos los mensajes antes de una caída accidental. Nos encontramos con una posibilidad de pérdida de mensajes al momento de hacer un failover a otro cluster debido a que la replicación de cluster linking es asincrónica. Para abordar esta problemática es necesario desarrollar una estrategia acorde a los procesos de la organización, que permita corroborar si hubo mensajes que no fueron replicados e identificarlos. En este momento debe aplicarse un plan de recuperación de mensajes que puede ejecutarse antes de hacer la promoción del cluster pasivo, o luego del fail-forward para disminuir el downtime.
Conclusión:
La replicación de clusters en entornos multi data-center es una estrategia efectiva para mejorar la resiliencia y la disponibilidad del sistema. El escenario propuesto, basado en el cluster linking y la replicación de tópicos, ofrece beneficios significativos al minimizar el impacto de los fallos y mejorar la eficiencia del proceso de failover. Al implementar soluciones de replicación como Cluster Linking, las organizaciones pueden fortalecer su infraestructura y enfrentar de manera más efectiva los desafíos de los entornos multi data-center.
